

As its original name suggests, a cache is a buffer in that it can store temporary data for quick access – although technically a cache and buffer are not the same thing. In simple terms a cache acts as a fast storage mechanism for temporary data in place of a slower source, the result of which can be reduced latencies and, in turn, increased performance.
To brutally re-phrase a quote from Babylon 5, “While all caches are buffers, not all buffers are caches” (Oh you big geek -ed). While a cache also buffers data in that the information is readily available in the cache for quick retrieval, a buffer is instead usually used to store data in transit and is designed to flush but retain its contents unless more data pushes it out. Mostly, they’re FIFO (first in first out), as you see with disk caches. Indeed, while hard drives today come with 8M, 16M, and 32M caches these are, in operation if not in name, buffers.
By contrast a cache will frequently continue to store whatever data is needed even as some of its contents come and go, and is used in conjunction with predictive algorithms to keep useful data where it’s needed most.
And on that note, just what are all those caches in your system and what do they do?
L1
The Level 1 cache, or L1, is built into your CPU and so runs at the same speed as the CPU. This is an expensive prospect to do, and as a result L1 caches aren’t very large. However they are the fastest cache in your system, and your CPU loves them. More than Vegemite loves toast, even.
In modern CPUs the L1 is frequently broken down into two specific dedicated caches: the instruction cache and the data cache.
The instruction cache, as the name suggests, caches instructions before they enter the fetch/decode/execution cycle. The data cache stores the results of calculations before being written back to the L2 cache and onto main memory. Together they can reduce latency for calculations that require instructions already in the instruction cache, or data already in the data cache, saving the need to source these from the L2 cache. Note: that is a simplistic view of cache operation – branching prediction allows the instruction prefetcher to load instructions into the L1 instruction cache in advance, while the L1 data cache can also be pre-emptively filled from the L2 cache in advance for data that is expected to be needed. It’s all part of the magic, and complexity, of modern CPU design.
Finally, the L1 cache is always dedicated solely to a particular processor, or to a particular core on a multi-core processor. It’s also tailored to the architecture, and size isn’t necessarily an indicator of performance. Commonly, modern CPUs like Intel’s Core2 use 32k for the L1 instruction and L1 data caches, for a total of 64k L1 cache. AMD’s Athlon64 and Phenom lines uses 64k for the L1 instruction and L1 data respectively, for a total of 128K.
L2 and L3
If instructions and data can’t be found in the L1 cache, the next step is the Level 2 cache. A loose definition of caches in general is that the larger they are, the greater the hit rate they provide at the cost of latency. This is a description apt for both L2 and L3 caches. Both are substantially larger than the L1 cache, but incur a higher latency.
The L2 is where competing processors from Intel and AMD start to differ more as well. By way of example, processors like Intel’s Core2 come with whopping great big L2 caches (4MB for the 65nm brethren, 6MB for the 45nm) per dual-core. The cache is also shared between the cores. So on a 45nm quad-core Core2, although the beast comes with 12MB of L2 cache, you have to remember a Core2 quad is literally two dual-cores slapped together, and the 12MB L2 cache actually comprises two 6MB L2 caches that can’t be shared between the two dual-cores. By comparison AMD’s current Athlon64 and Phenom lines use dedicated L2 caches specific to each core, with 1MB cache per core on the FX-62 and 512KB per core on the Phenom.
Additionally the Phenom incorporates a 2MB shared Level 3 cache, which is really just a larger shared L2, but does allow the Phenoms to benefit from super-fast L1 and L2 caches specific to the processing tasks of each core while also gaining from a fast shared cache in the L3 between cores. It is, ultimately, a good design – and it’s not surprising that Intel would appear to be learning from AMD here, as Nehalem looks to be providing smaller dedicated L2 caches per core and adding a large shared L3 cache instead when it arrives.
Shared caches have a number of benefits – they allow one core to use more than its share of cache if the other cores are using less, and they facilitate sharing of data between cores, negating the need and penalty of going to main memory.
Main memory
The main memory in your system, even though you may not think of it this way, is also a cache. It’s the largest, and slowest, cache in your system. Off the CPU die and into the void of motherboard busses, main memory is a heck of a lot slower, but in turn you can load it up with cheap (by comparison to the cost of building memory on the CPU) RAM and store all the running data of your operating system and applications for the CPU to fetch as needed.
And we all know what happens when our operating system (gosh, here’s looking at you Vista) demands more memory than the system has installed – it’s off to the hard drive.
Hard drives
Hard drives are also a cache, of a particular fancy – in literal terms they are long-term non-volatile storage, and are also both larger and slower by an order of magnitude over main memory. They continue the ‘greater hits, slower access’ definition, with in fact a hit-rate of 100 per cent, if you think about it.
Really if RAM was non-volatile, voluminous, and cheap as chips you wouldn’t need a hard drive. This is of course the tenet behind SSDs, but they are just emerging, and it will be a while before they can match the volumes of a traditional hard drive.
Then, on the drives, we frequently have the page file (or swap) which is roughly translated as RAM-on-your-disk. When main memory is full, the operating system maps data in and out of the swapfile, using it as an extension of main memory. So here we have another cache, a virtual one, caching data from main memory and stored as a file on the drive itself.
Finally, of course, hard drives have their own on-board RAM that’s used to buffer data in transit to and from the system. These literally empty almost as fast as they can be filled, and while the portion used for read caching is questionable, write caching can have a big impact. Here the drive can tell the system that a write has been completed even if it actually hasn’t been written to the drive yet, and in doing so allow the operating system to move onto the next write or task.
Applications
Much like using hard drive space as a buffer for memory with the page file, perversely the reverse is also true when it comes to the operating system and applications using main memory to buffer access to the disk. In one sense this is a means to effectively extend the drive’s own cache, but also to keep data coming to and from drives in main memory where, if needed again, is on-hand rather than needing to go to the hard drive.
All operating systems set aside a portion of main memory as a disk cache, although technically it’s a buffer. Here, the operating system can perform writes to the disk cache in memory, get an immediate response that the task is complete, and move on while the cache is later flushed to disk by the cache manager (usually handled by the operating system’s kernel).
Finally, it’s not just the operating system that will use main memory for caching – applications do as well. Take your browser, for example, which will use a small portion of memory for caching objects in memory in addition to a disk cache. Other applications that will use memory caching include web servers, proxies, bittorrent clients, video software, media players, and more.
All up, the cache is a concept and mechanism that is integral to the operation of your machine, and a means to maximise peformance where possible in any given subsystem.
Associatively speaking
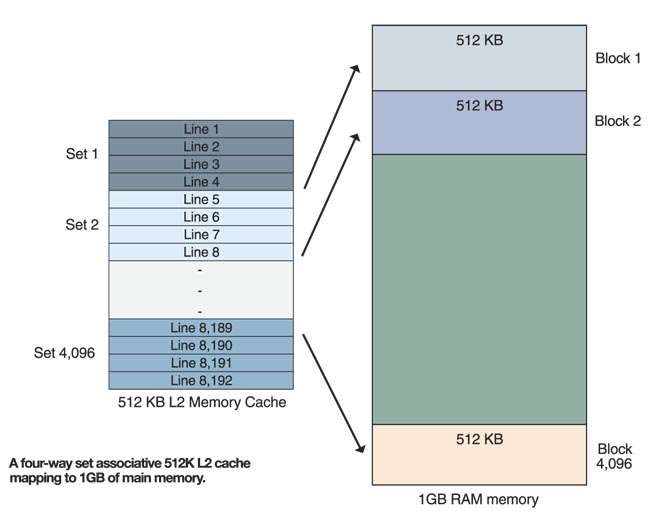
In order to cache data from main memory the L1, L2 and L3 cache use what’s known as set associative mapping. Here a cache is divided up into a number of 64-byte lines (typically 8192), and broken up into blocks. Depending on if the cache is two-way, four-way, eight-way, or 16-way set associative on a 512K cache there will be 4096, 2048, 1024, or 512 blocks respectively. This associativity (you’re making up words again –ed) specifies how main memory is mapped to the cache – in four-way set associative, each block contains four lines, eight-way eight lines and so on. Main memory is divided into the same number of blocks as the cache, and as data is requested it’s loaded in 64-byte chunks into the relevant block in the cache, with up to two, four, eight, or 16 lines able to be used for that particular memory block. If data is read from memory and its corresponding cache lines are full, one or more of the lines will be emptied to accommodate the new data – but if the CPU requests data from those main memory locations that are mapped in the cache, it can be retrieved from the cache instead of main memory and thus negate the latency of accessing main memory.
By the sounds of it opting for 16-way associative would be better than eight-way, four-way, or two-way as there are more lines to cache more data for a given mapped memory block. But unless the size of the cache also increases, this will increase the size of each block mapped to main memory – so although there are more lines, each block now manages a larger chunk of main memory, reducing the granularity of the cache. Which is why there’s no golden rule here, and both Intel and AMD approach associativity differently depending on their processors.

Typically, L1 caches use two-way set associative while L2 and L3 caches, depending on the processor, use four-way, eight-way, and 16-way set associative.
Hit and miss
A cache isn’t a wonder tool, much though it may seem like one. After all, they are only as useful as the data they contain – if what the CPU is looking for isn’t in a cache, data needs to be fetched from the next cache down and, ultimately, main memory. Data that is found within a cache is called a ‘hit’, while data that is requested and not found is called a ‘miss’. It’s interesting to note that your machine, clean as it is when you turn it on, starts on a miss for all caches until the first data is read in from main memory. After that, it’s a jolly old game of cache management logic attempting to predict what will be needed next while your operating system and programs scatter themselves among main memory and issue instructions while they run.


.jpg&h=142&w=230&c=1&s=1)
.jpg&h=142&w=230&c=1&s=1)






.jpg&w=100&c=1&s=0)












